
Run Configurations
Execute Jobs / Transformations on specific nodes or in a Pentaho Cluster ..
Pentaho Data Integration provides advanced clustering and partitioning capabilities that allow organizations to scale out their data integration deployments.
In this guided demonstration, you will:
• Configure Master & Slave Nodes
• Execute RUN Configurations
So lets start scaling out by adding some servers (nodes).
These can be defined as either:
• Master: node is responsible for distributing work among the worker nodes and ensuring high availability and scalability of the system.
• Slave (Worker): node in Pentaho is an instance that can execute Pentaho work items, such as PDI jobs and transformations, with parallel processing, dynamic-scalability, load-balancing, and dependency-management in a clustered environment
Master Node
You can indiviually start the carte instances or execute the following command to deploy all 3 at the same time .
cd
cd ~/Scripts
./start_carte.shIn a terminal execute the following command.
cd
cd ~/Pentaho/design-tools/data-integration
sh carte.sh localhost 12000
Slave Nodes
In a new terminal execute the following command (Slave A).
cd
cd ~/Pentaho/design-tools/data-integration
sh carte.sh localhost 12100
In a new terminal execute the following command (Slave B).
cd
cd ~/Pentaho/design-tools/data-integration
sh carte.sh localhost 12200
You should now have 3 terminals, each running a Carte instance.
Please dont close the terminals ..!
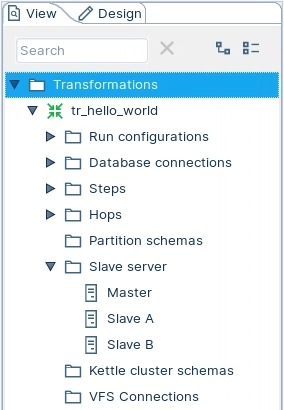
Open the tr_hello_world transformation.
Select the View tab
Highlight the Slave server option; right mouse click and select: New
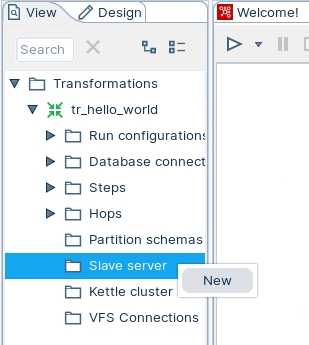
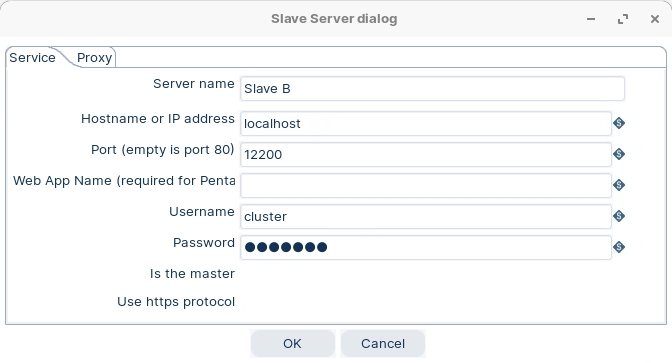
Server name
The name of the slave server.
Hostname or IP address
The address of the device to be used as a slave.
Port (empty is port 80)
Defines the port you are for communicating with the remote server. If you leave the port blank, 80 is used.
Web App Name (required for Pentaho Server)
Leave this blank if you are setting up a Carte server. This field is used for connecting to the Pentaho server.
User name
Enter the user name for accessing the remote server.
Password
Enter the password for accessing the remote server. (cluster/cluster)
Is the master
Enables this server as the master server in any clustered executions of the transformation.
Below are the proxy tab options:
Proxy server hostname
Sets the host name for the proxy server you are using.
The proxy server port
Sets the port number used for communicating with the proxy.
Ignore proxy for hosts: regexp | separated
Specify the server(s) for which the proxy should not be active. This option supports specifying multiple servers using regular expressions. You can also add multiple servers and expressions separated by the ' | ' character.
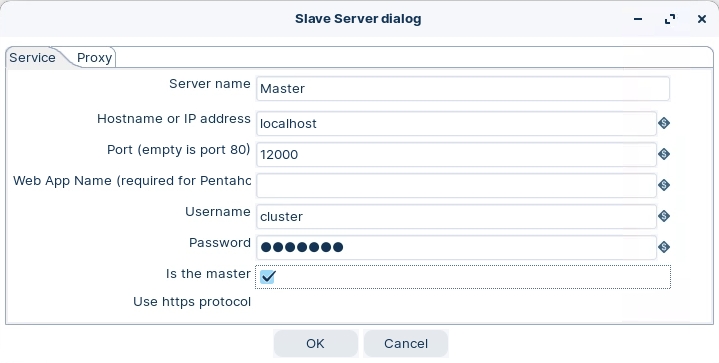
Master Node
Enter the following settings to configure the Master node:
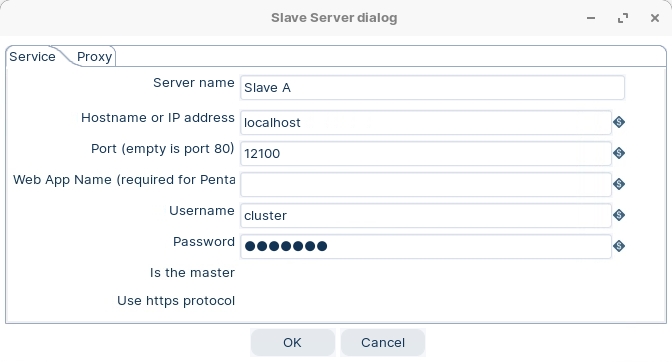
Slave Nodes
Enter the following settings to configure the Slave node A:
Enter the following settings to configure the Slave node B:
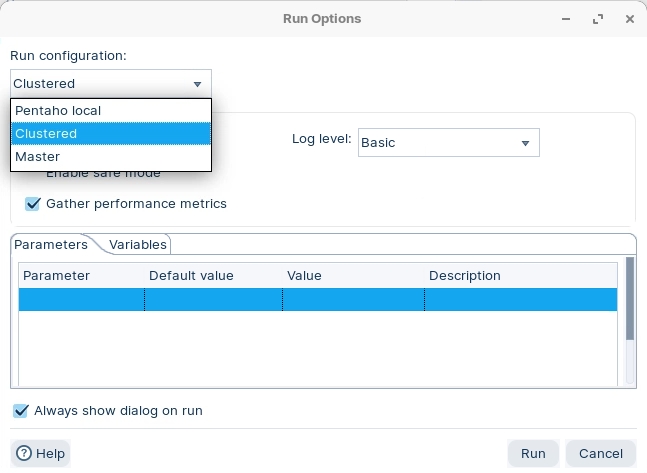
Ok .. now we're ready to RUN transformations on specific nodes.
Now we have our 3 nodes up and running, lets configure some RUN configurations to execute our Transformations on specific nodes.
Some ETL activities are lightweight, such as loading in a small text file to write out to a database or filtering a few rows to trim down your results. For these activities, you can run your transformation locally using the default Pentaho engine.
Some ETL activities are more demanding, containing many steps calling other steps or a network of transformation modules. For these activities, you can set up a separate Pentaho Server dedicated for running transformations using the Pentaho engine.
Other ETL activities involve large amounts of data on network clusters requiring greater scalability and reduced execution times. For these activities, you can run your transformation using the Spark engine in a Hadoop cluster.
Pentaho local is the default run configuration. It runs transformations with the Pentaho engine on your local machine. You cannot edit this default configuration.
Ensure you have configured the Nodes.
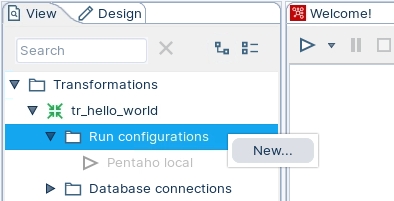
To create a new run configuration, right-click on 'Run configurations' folder and select New.
Enter the following configuration details, ensuring that you select the Pentaho (KETTLE) engine.
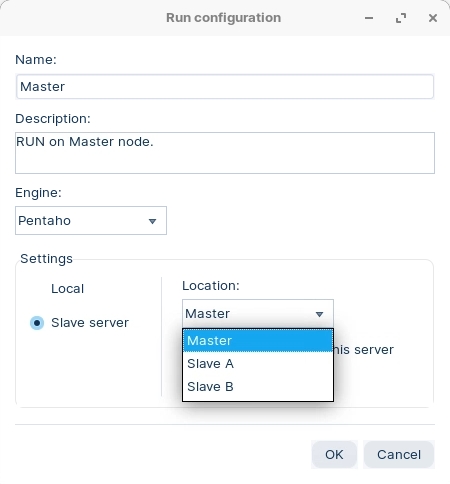
When you come to RUN the transformation, select Master node.
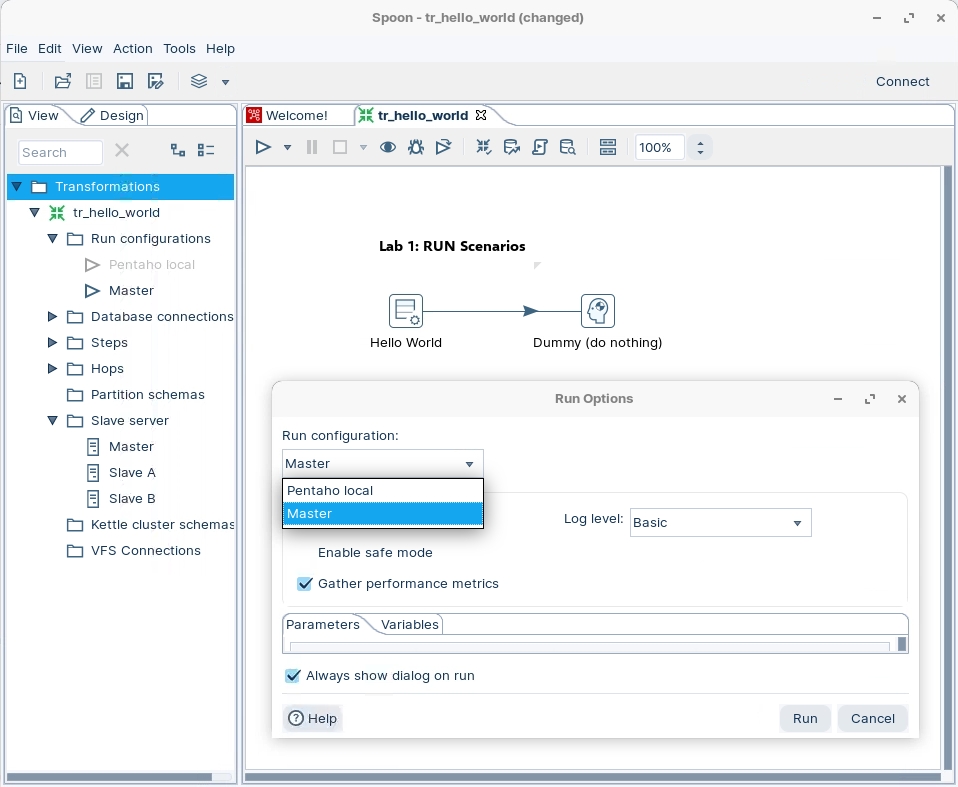
As you can see from the Results:
Transformation is executed on the Master Node
As Monitor tab displays the Step Metrics
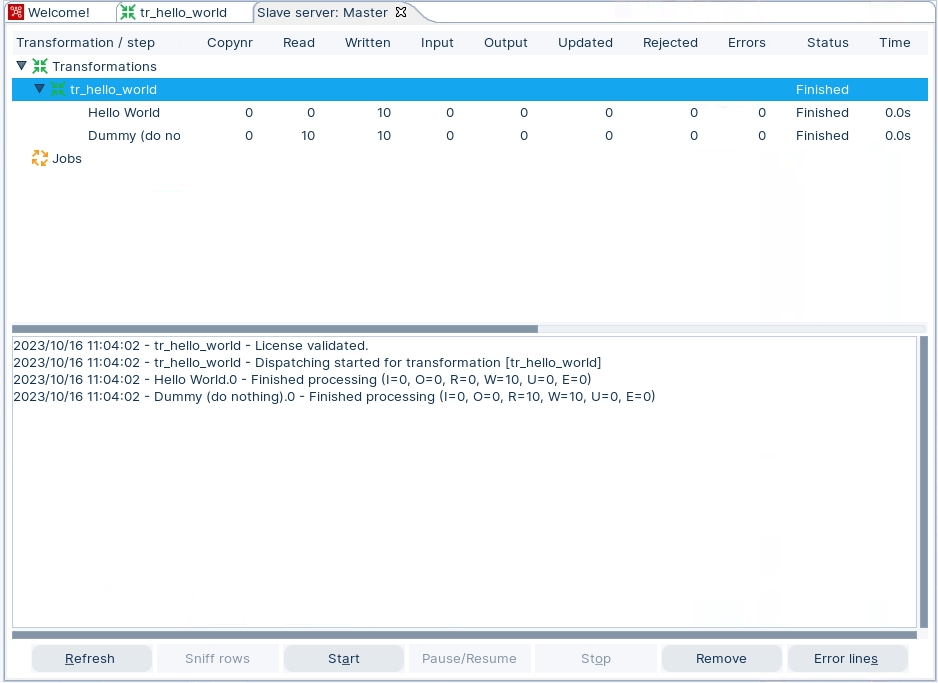
Take a look at the Master Terminal.
Give it a go with other RUN configurations .. Just Slave A / B
A cluster schema is essentially a collection of slave servers. In each schema, you need to pick at least one slave server that we will call the Master slave server or master.
The master is also just a carte instance but it takes care of all sort of management tasks across the cluster schema. In the Spoon GUI, you can enter this metadata as well once you started a couple of slave servers.
The workflow in a clustered Pentaho transformation is as follows:
• The job entry or the transformation connects to the cluster master node, which is responsible for coordinating the execution of the transformation steps on the cluster slave nodes.
• The master node sends the transformation metadata and the cluster schema to the slave nodes, and assigns each step to one or more nodes based on the cluster schema.
• The slave nodes execute the assigned steps and exchange data with each other using sockets or shared files, depending on the partitioning method and the clustering plugin used.
• The master node monitors the progress and status of the slave nodes, and collects logging information and performance metrics from them.
• The master node reports the outcome of the transformation execution to the job entry or the transformation that initiated it.
Cluster Schema
To create a new run configuration, right-click on 'Kettle cluster schemas' folder and select New.
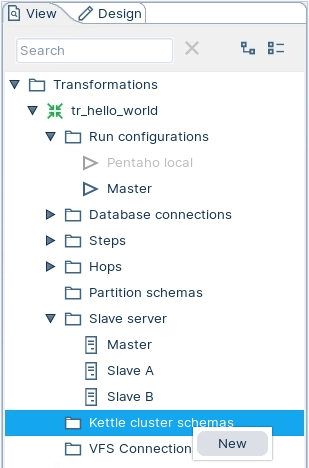
Enter the following configuration details.
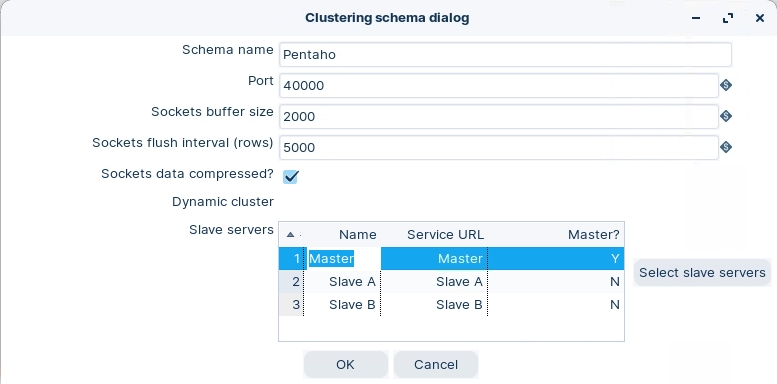
Schema name
The name of the clustering schema
Port
Specify the port from which to start numbering ports for the slave servers. Each additional clustered step executing on a slave server will consume an additional port. Note: To avoid networking problems, make sure no other networking protocols are in the same range.
Sockets buffer size
The internal buffer size to use
Sockets flush interval rows
The number of rows after which the internal buffer is sent completely over the network and emptied.
Sockets data compressed?
When enabled, all data is compressed using the Gzip compression algorithm to minimize network traffic
Dynamic cluster
If checked, a master Carte server will perform failover operations, and you must define the master as a slave server in the field below. If unchecked, Spoon will act as the master server, and you must define the available Carte slaves in the field below.
Slave Servers
A list of the servers to be used in the cluster. You must have one master server and any number of slave servers. To add servers to the cluster, click Select slave servers to select from the list of available slave servers.
To create a new run configuration, right-click on 'Run configurations' folder and select New.
Enter the following configuration details, ensuring that you select the Pentaho (KETTLE) engine.
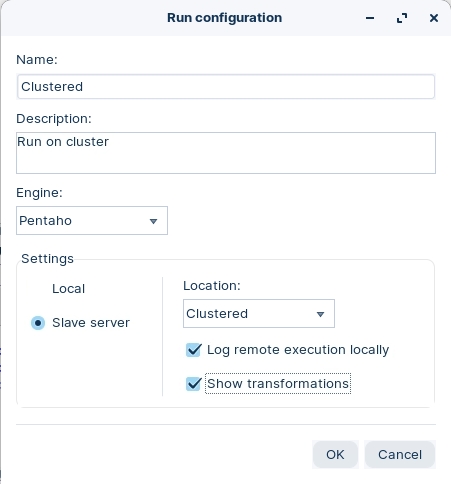
You can set for the logs to be created locally.
The 'Show transformations' option is useful for documentation, as diagrams illustrating the dataflow are created.
A Carte cluster consists of two or more Carte slave servers and a Carte master server. A Carte server is a lightweight web service that can execute jobs and transformations remotely. A Carte cluster can speed up the processing of transformations by distributing the work across multiple Carte slave nodes, while the Carte master node tracks the progress. A Carte cluster can be static or dynamic. A static Carte cluster has a fixed schema that specifies the nodes in advance. A dynamic Carte cluster allows you to add or remove nodes at runtime.
Pentaho can also connect to other types of clusters, such as Hadoop clusters, to leverage big data processing capabilities. For example, Pentaho can connect to secured and unsecured MapR clusters, which are Hadoop distributions that provide high performance, reliability, and security. To connect to a MapR cluster, you need to configure the cluster, install any required services and service client tools, and test the cluster
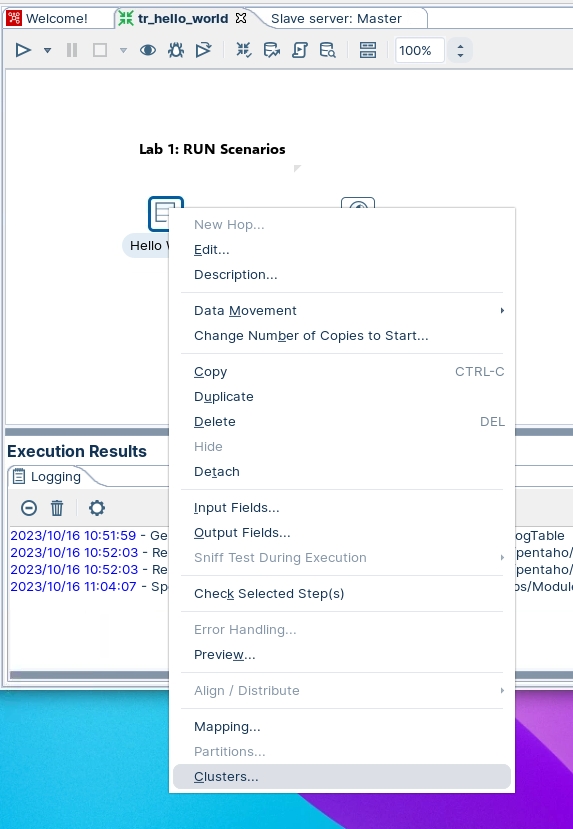
Highlight the Hello World step, right mouse click and select the option Clusters from the drop down menu.
Select 'Pentaho' cluster schema.
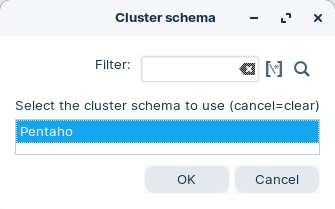
Notice that the step will indicate the number of Slave nodes it will be executed on.

RUN the transformation with Clustered configuration.
A bunch of Tabs will appear for each node which display the Metrics and Metadata transformations.
Take a look at the Tabs (example below is for Slave A).
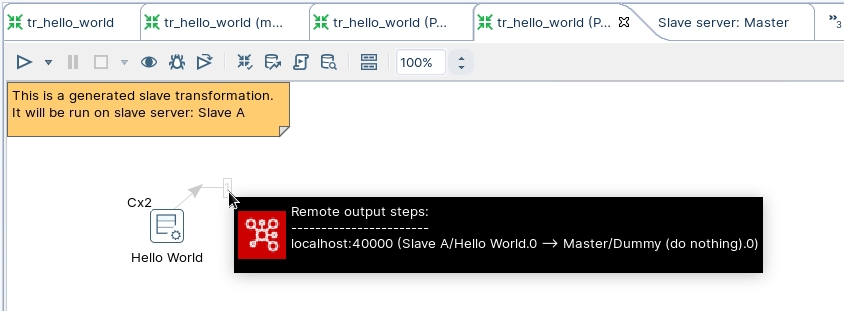
Here you can see that the records are streamed from Slave node A back to the Master node.
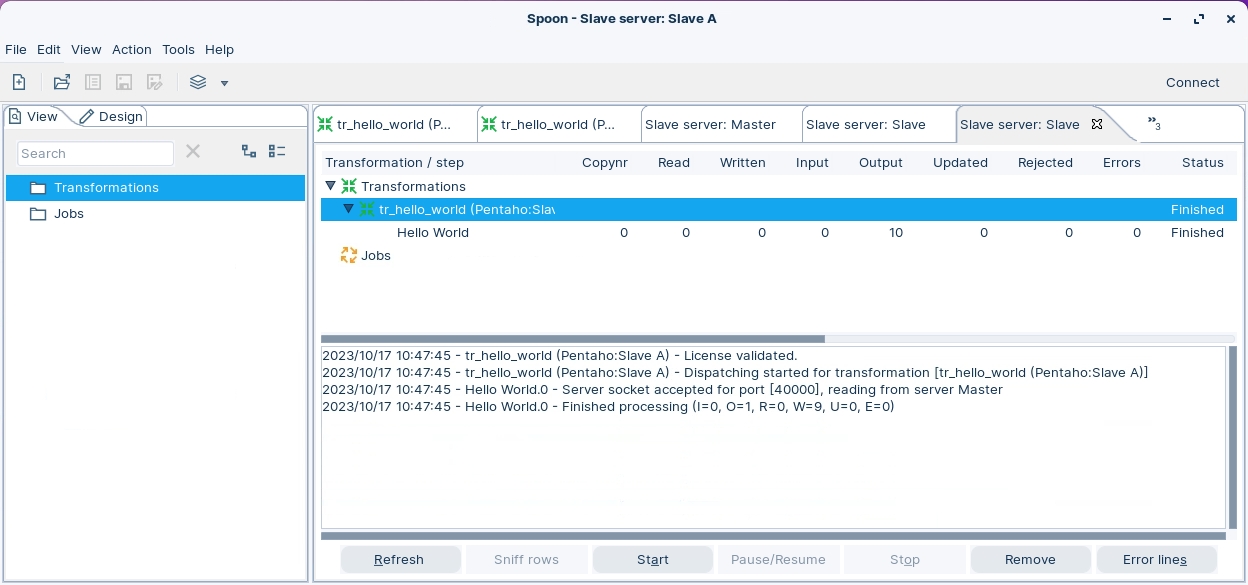
The metrics indicate that Slave Node A ingested the records.
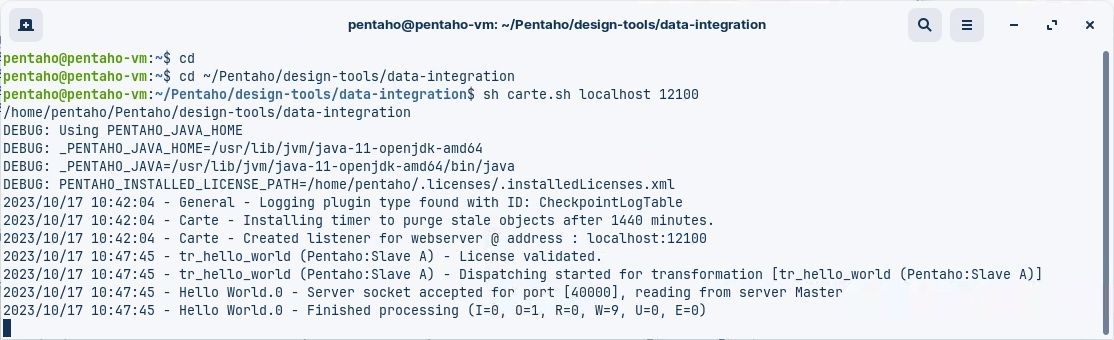
The Logs indicate Slave A successfully read the transformation metadata dispatched from the Master node and executed the step, streaming the resulting dataset back to the Master node.
Last updated