
Database Join
A self join or recursive join .. or is it ?
Workshop - Database Join
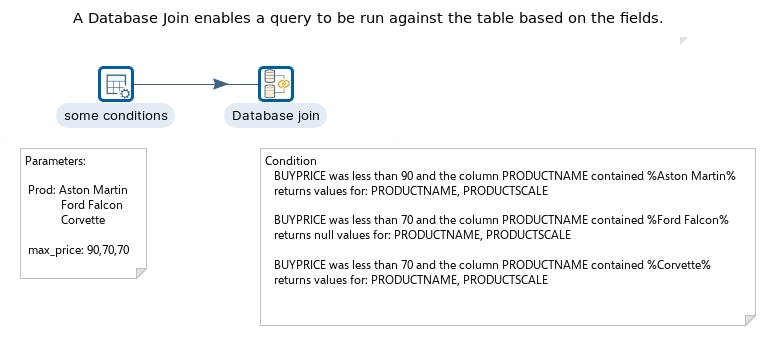
Searching for information in databases, text files, web services, and so on, is a very common task. In this workshop we're going to query the Products table for products are listed below a set buy price.
The database join isn't actually a join, but a series of queries against the table based on set conditions. Be aware this results in a performance hit.

The following content has been automatically generated by an AI system and should be used for informational purposes only. We cannot guarantee the accuracy, completeness, or timeliness of the information provided.
Any actions taken based on this content are at your own risk. We recommend seeking qualified expertise or conducting further research to validate and supplement the information provided.
Create a new Transformation
Any one of these actions opens a new Transformation tab for you to begin designing your transformation.
By clicking File > New > Transformation
By using the CTRL-N hot key
Data grid
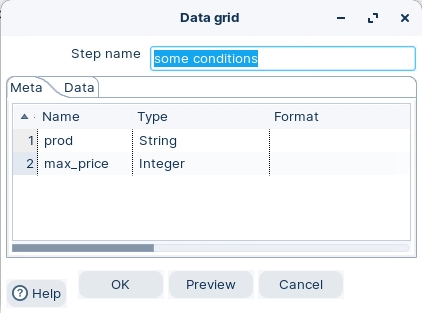
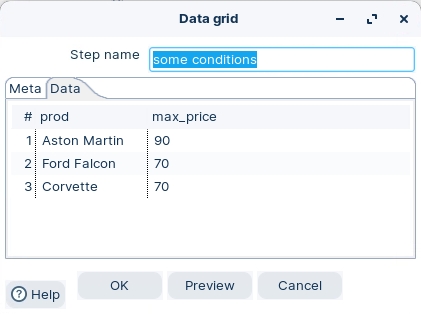
The Data grid step allows you to enter a static list of rows in a grid. This is usually done for testing, reference or demo purposes.
Drag the Data grid step onto the canvas.
Open the Data grid properties dialog box.
Ensure the following details are configured, as outlined below:



Last updated