
Job - Hello World
What's a Pentaho Job ..
Workshop - Job
In this workshop, we're going to create & configure a simple Job.
The concepts learnt, help to build the foundation necessary for creating any Job.
Create a new Job.
Add entries and configure hops.
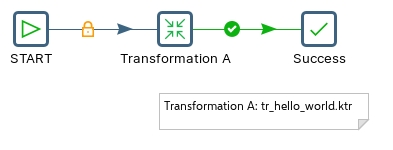
To create a new Job:
In Spoon, click File > New > Job.
Drag the ‘START’ job entry onto the canvas.



Last updated