
Text File Input
Onboarding text files ..
Workshop - Text File Input
Some of the Orders data that Steel Wheels process are in a text format. In this workshop, you will flatten the list, create capture groups, replace text, and finally format the order_value.
In this workshop, you will configure the following steps:
Text File Input
Flattener
RegEx Evaluation
Replace in String
Select values
The lab gives you an idea of some of the steps required to load flat files into a database table.

So what do we need to do to get this into a database table?

The following content has been automatically generated by an AI system and should be used for informational purposes only. We cannot guarantee the accuracy, completeness, or timeliness of the information provided.
Any actions taken based on this content are at your own risk. We recommend seeking qualified expertise or conducting further research to validate and supplement the information provided.
To create a new Transformation
Any one of these actions opens a new Transformation tab for you to begin designing your transformation.
By clicking File > New > Transformation
By using the CTRL-N hot key
Text File Input
The Text File Input step is used to read data from a variety of different text-file types. The most commonly used formats include Comma Separated Values (CSV files) generated by spreadsheets and fixed width flat files.
The Text File Input step provides you with the ability to specify a list of files to read, or a list of directories with wild cards in the form of regular expressions. In addition, you can accept filenames from a previous step making filename handling more even more generic.
Start Pentaho Data Integration.
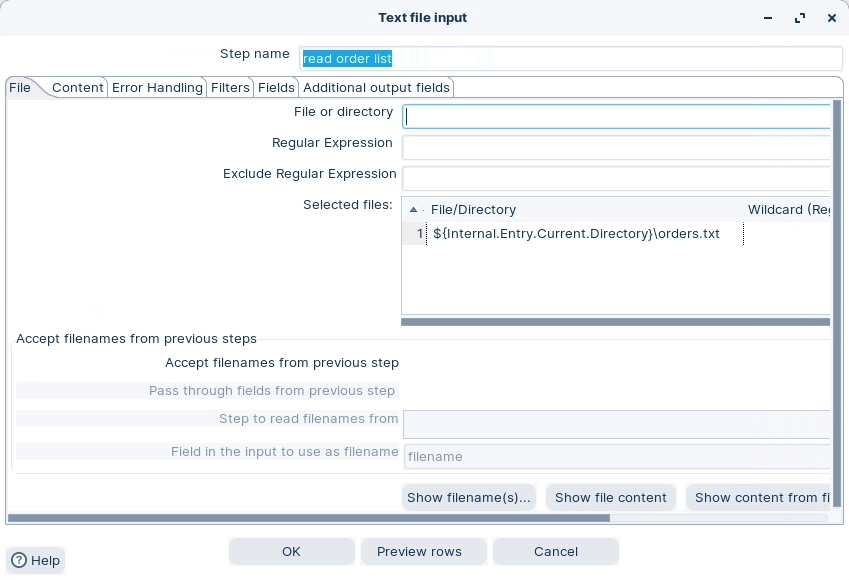
Drag the ‘Text File Input’ step onto the canvas.
Double-click on the step, and configure the following properties:
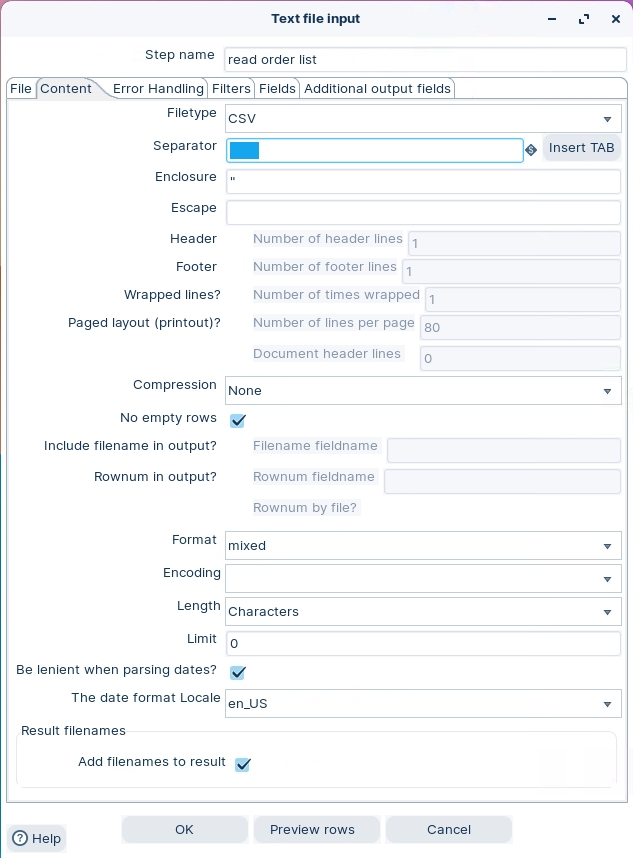
Click on the ‘Content’ tab and configure the following properties:
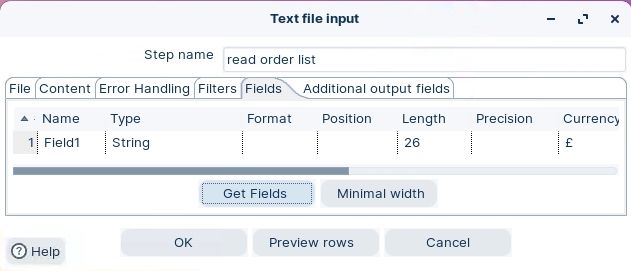
Click on ‘Get Fields’ button.
Click on the ‘Fields’ tab and notice the following properties:
Close the Step.
➡️ Next: Flatten rows






Last updated