
Delete DB table
Workshop - Delete DB
Sometimes you might have to delete data from a table. If the operation to do it is simple, for example:
DELETE FROM ORDERS_TABLE WHERE STATUS='Shipped'
Or
DELETE FROM TMP_TABLE
You could simply execute it by using an SQL job entry or an Execute SQL script step. If you face the second of the above situations, you can even use a Truncate table job entry.
For more complex scenarios, you should use the Delete step.
Steel Wheels are launching a campaign, focusing on Customers who have ordered more than 50 of each of their various Productlines.


The following content has been automatically generated by an AI system and should be used for informational purposes only. We cannot guarantee the accuracy, completeness, or timeliness of the information provided.
Any actions taken based on this content are at your own risk. We recommend seeking qualified expertise or conducting further research to validate and supplement the information provided.
Create a new Transformation
Any one of these actions opens a new Transformation tab for you to begin designing your transformation.
By clicking File > New > Transformation
By using the CTRL-N hot key
Inspect the data
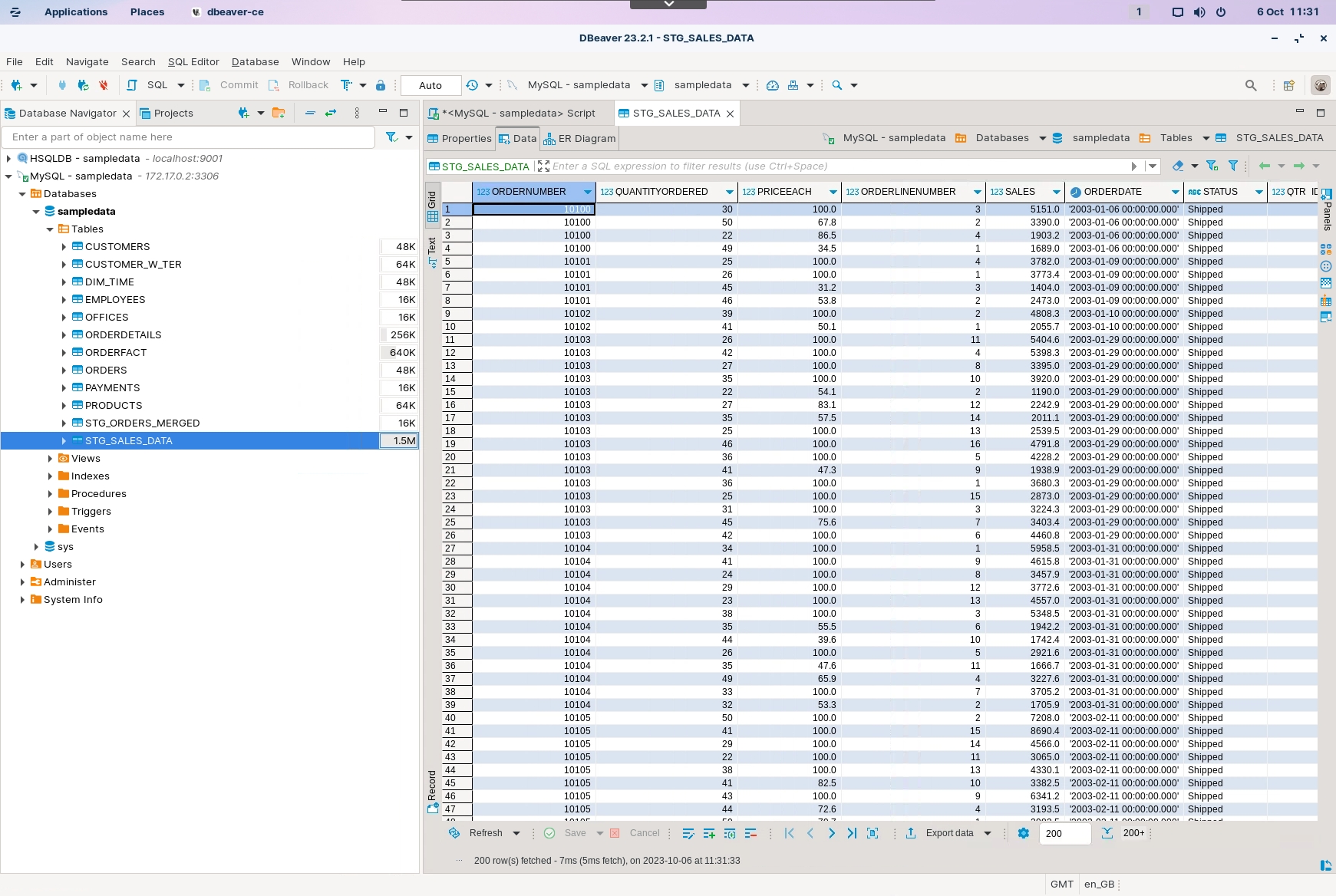
Before we kick off .. lets take a look at the stg_sales_data table data to get an understanding of what results to expect..
View the STG_SALES_DATA data.
Execute the following statement.
select * from STG_SALES_DATA
where QUANTITYORDERED > '50';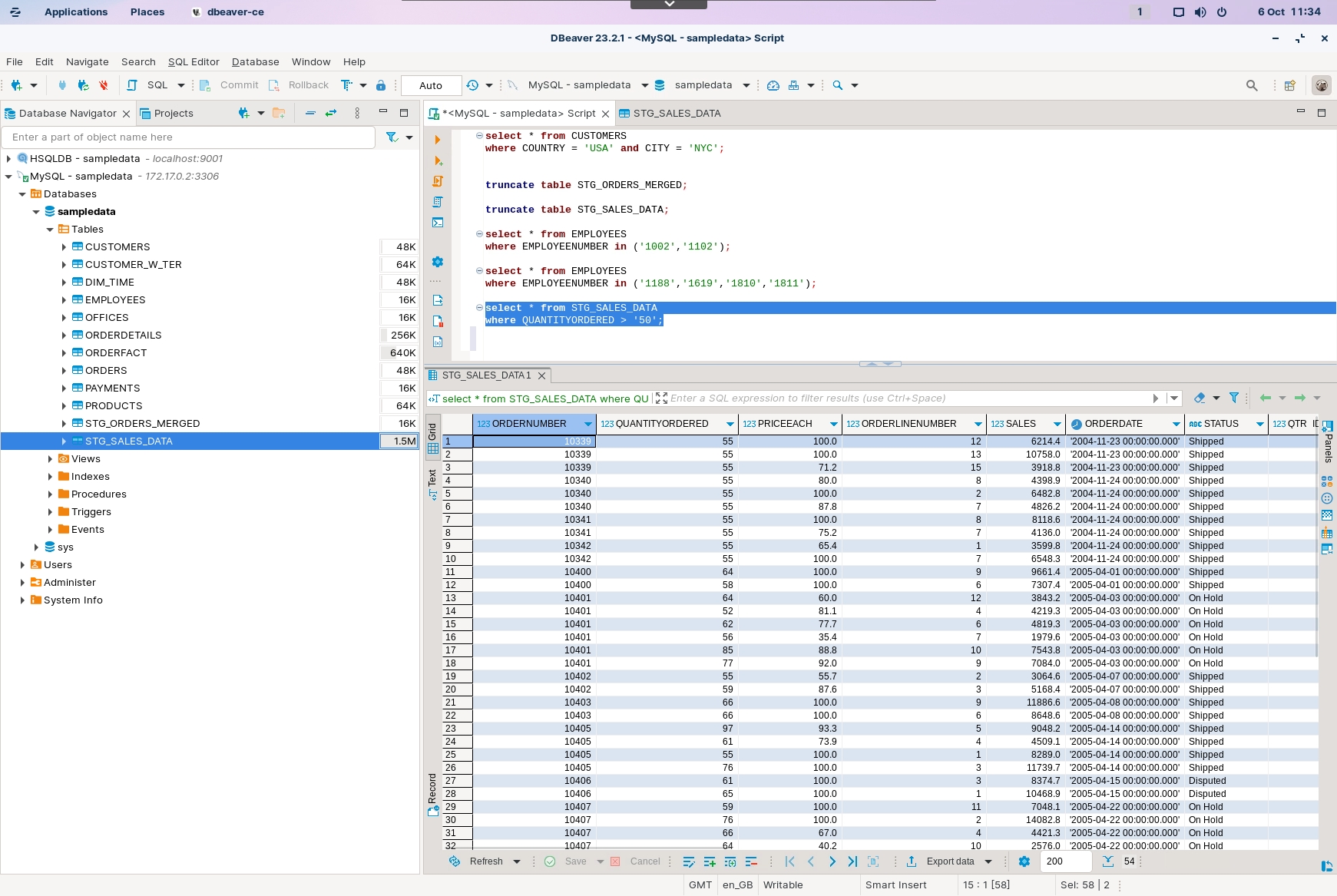





Last updated